pages/blog/k8s-at-home.md (view raw)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 |
---
template:
slug: k8s-at-home
title: Setting up a multi-arch Kubernetes cluster at home
subtitle: My self-hosted infra, given the cloud native™ treatment
date: 2021-06-19
---
**Update 2021-07-11**: It was fun while it lasted. I took down the
cluster today and probably won't go back to using it. It was way too
much maintenance, and Kubernetes really struggles with just 1GB of RAM
on a node. Constant outages, volumes getting corrupted (had to `fsck`),
etc. Not worth the headache.
I still remember my
[Lobste.rs](https://lobste.rs/s/kqucr4/unironically_using_kubernetes_for_my#c_kfldyw)
comment, mocking some guy for running Kubernetes for his static blog --
it _is_ my highest voted comment after all. But to be fair, I'm not
running mine for a static blog. In fact, I'm not even hosting my blog on
the cluster; but I digress. Why did I do this anyway? Simply put: I was
bored. I had a 4 day weekend at work and with nothing better to do to
other than play Valorant, and risk losing my hard earned Bronze 2 -- I
decided to setup a K8s cluster. These are the nodes in use:
- `fern`: Raspberry Pi 4B (armhf, 4GB, 4 cores)
- `jade`: Oracle VM (amd64, 1GB, 1 core)
- `leaf`: Oracle VM (amd64, 1GB, 1 core)
The Oracle machines are the free tier ones. It's great -- two static
public IPs, 50 gigs of boot volume storage on each + up to 100 gigs of
block volume storage. All for free.[^1] Great for messing around.
[^1]: No, this is not an advertisement.
Since my RPi is behind a CG-NAT, I'm running a Wireguard mesh that looks
something like this:
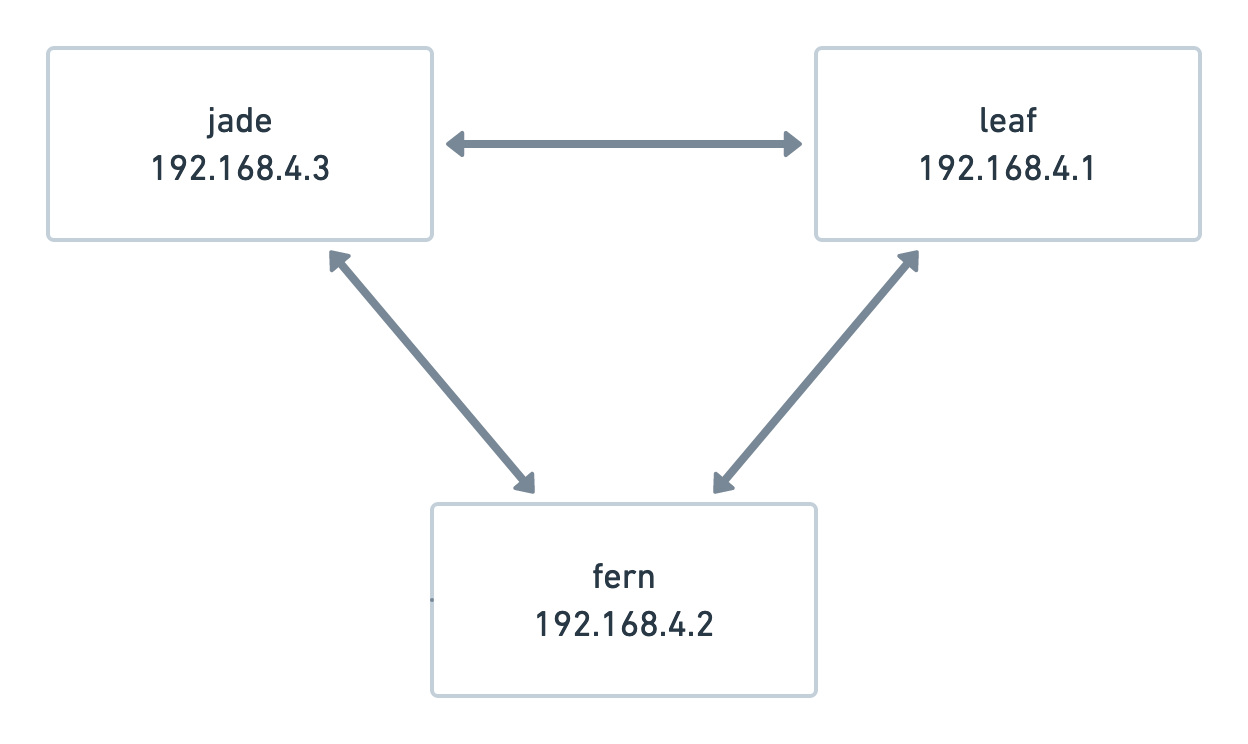
Wireguard is fairly trivial to set up, and there are tons of guides
online, so I'll skip that bit.
## setting up the cluster
I went with plain containerd as the CRI. Built v1.5.7 from source on all
nodes.
I considered running K3s, because it's supposedly "lightweight". Except
it's not really vanilla Kubernetes -- it's more of a distribution. It
ships with a bunch of things that I don't really want to use, like
Traefik as the default ingress controller, etc. I know components can be
disabled, but I couldn't be arsed. So, `kubeadm` it is.
```
kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.4.2
```
Since I'm going to be using Flannel as the CNI provider, I set the pod
network CIDR to Flannel's default. We also want the Kube API server to
listen on the Wireguard interface IP, so specify that as well.
Now, the `kubelet` needs to be configured to use the Wireguard IP, along
with the correct `resolv.conf` on Ubuntu hosts (managed by
`systemd-resolvd`)[^2]. This can be set via the `KUBELET_EXTRA_ARGS`
environment variable, in `/etc/default/kubelet`, for each node:
```shell
# /etc/default/kubelet
KUBELET_EXTRA_ARGS=--node-ip=192.168.4.X --resolv-conf=/run/systemd/resolve/resolv.conf
```
[^2]: I hate systemd with such passion.
Nodes can now be `kubeadm join`ed to the control plane. Next, we setup
the CNI. I went with Flannel because it has multi-arch images, and is
pretty popular. However, we can't just apply Flannel's manifest -- it
must be configured to use the `wg0` interface. Edit `kube-flannel.yaml`:
```patch
...
containers:
- args:
- --ip-masq
- --kube-subnet-mgr
+ - --iface=wg0
...
```
If everything went well, your nodes should now show as `Ready`. If not,
well ... have fun figuring out why. Hint: it's almost always networking.
Make sure to un-taint your control plane so pods can be scheduled
on it:
```
kubectl taint nodes --all node-role.kubernetes.io/master-
```
Finally, set the `--leader-elect` flag to `false` in your control
plane's
`/etc/kubernetes/manifests/kube-{controller-manager,scheduler}.yaml`.
Since these are not replicated, leader election is not required. Else,
they attempt a leader election, and for whatever reason -- fail.
Horribly.[^3]
[^3]: https://toot.icyphox.sh/notice/A8NOeVqMBsgu5DWLZ2
## getting the infrastructure in place
The cluster is up, but we need to set up the core components -- ingress
controller, storage, load balancer, provisioning certificates, container
registry, etc.
### MetalLB
The `LoadBalancer` service type in Kubernetes will not work in a bare
metal environment -- it actually calls out to the respective cloud
provider's proprietary APIs to provision a load balancer.
[MetalLB](https://metallb.universe.tf/) solves this by well, providing
an LB implementation that works on bare metal.
In essence, it makes one of your nodes attract all the traffic,
assigning each `LoadBalancer` service an IP from a configured address
pool (not your node IP). In my case:
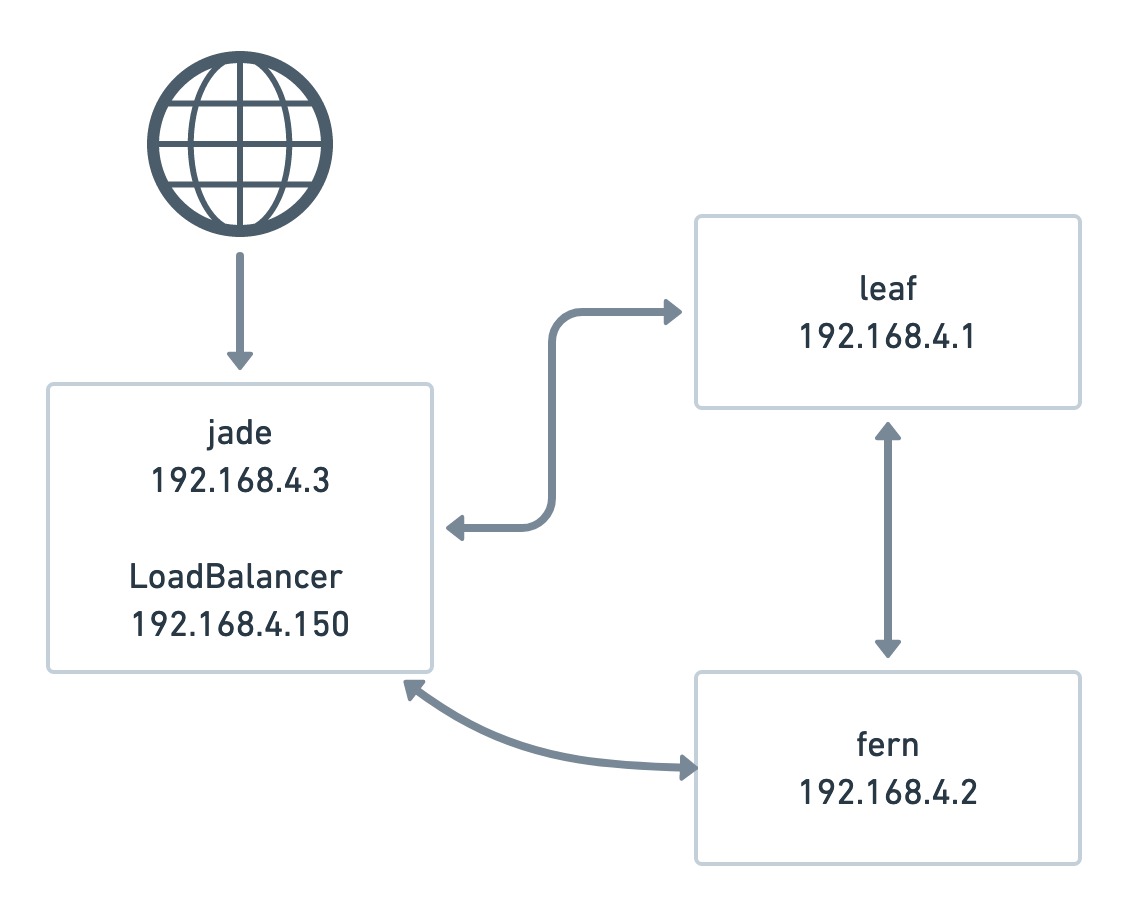
However, this assumes that our load balancer node has a public IP. Well
it does, but we're still within our Wireguard network. To actually
expose the load balancer, I'm running Nginx. This configuration allows
for non-terminating SSL passthrough back to our actual ingress (up
next), and forwarding any other arbitrary port.
```nginx
stream {
upstream ingress443 {
server 192.168.4.150:443;
}
upstream ingress80 {
server 192.168.4.150:80;
}
server {
listen 443;
proxy_pass ingress443;
proxy_next_upstream on;
}
server {
listen 80;
proxy_pass ingress80;
proxy_next_upstream on;
}
}
```
DNS can now be configured to point to this node's actual public IP, and
Nginx will forward traffic back to our load balancer.
### Nginx Ingress Controller
Once MeltalLB is setup, `ingress-nginx` can be deployed. Nothing of note
here; follow their [docs](https://kubernetes.github.io/ingress-nginx/deploy/).
Each ingress you define will be exposed on the same `LoadBalancer` IP.
### Longhorn
Storage on bare metal is always a pain in the wrong place. Longhorn is
pretty refreshing, as it literally just works. Point it to your block
volumes, setup a `StorageClass`, and just like that -- automagic PV/C
provisioning. Adding block volumes can be done via the UI, accessed by
portforwarding the service:
```
kubectl portforward service/longhorn-frontend -n longhorn-system 8080:80
```
There's just one catch -- at least, in my case. They don't have armhf
images, so all their resources need:
```yaml
nodeSelector: kubernetes.io/arch=amd64
```
Consequently, all pods using a PVC can only run on non-armhf nodes. This
is a bummer, but I plan to switch the RPi over to a 64-bit OS
eventually. This cluster only just got stable-ish -- I'm not about to
yank the control plane now.
### cert-manager
Automatic certificate provisioning. Nothing fancy here. Follow their
[docs](https://cert-manager.io/docs/installation/kubernetes/).
## application workloads
We did _all_ of that, for these special snowflakes. I'm currently
running:
- [radicale](https://radicale.org): CalDAV/CarDAV server
- [registry](https://github.com/distribution/distribution): Container
registry
- [yarr](https://github.com/nkanaev/yarr): RSS reader
- [fsrv](https://github.com/icyphox/fsrv): File host service
- [znc](https://znc.in): IRC bouncer
I'm in the process of moving [Pleroma](https://pleroma.social) and
[lms](https://github.com/epoupon/lms/) to the cluster. I'm still
figuring out cgit.
## closing notes
That was a lot! While it's fun, it certainly feels like a house of
cards, especially given that I'm running this on very low resource
machines. There's about 500 MB of RAM free on the Oracle boxes, and about
2.5 GB on the Pi.
All things said, it's not terribly hard to run a multi-arch cluster,
especially if you're running arm64 + amd64. Most common tools have
multi-arch images now. It's just somewhat annoying in my case -- pods
using using a PVC can't run on my Pi.
Note that I glossed over a bunch of issues that I faced: broken cluster
DNS, broken pod networking, figuring out how to expose the load
balancer, etc. Countless hours (after the 4 days off) had to be spent
solving these. If I had a penny for every time I ran `kubeadm reset`,
I'd be Elon Musk.
Whether this cluster is sustainable or not, is to be seen. However, it
is quite nice to have your entire infrastructure configured in a single
place: https://github.com/icyphox/infra
```
~/code/infra
▲ k get nodes
NAME STATUS ROLES AGE VERSION
fern Ready control-plane,master 7d11h v1.21.1
jade Ready <none> 7d11h v1.21.1
leaf Ready <none> 7d11h v1.21.1
```
|